来源:www.wangzhan.net.cn 作者:笔者小丹 时间:2020-05-19 11:21:53 浏览:3530次
搜索引擎的存在是为了发现,抓取,整合互联网中的内容,在用户进行提出问题进行搜索时候能够快速的为用户提出相关的结果展示。为了让我们的网站能够展示在搜索引擎结果中,我们的内容必须要对搜索引擎友好,可见性。也就是说在SEO优化的难题中,首先是要让搜索引擎发现我们的网站,否则我们的网站内容则永远不可能出现的搜索引擎结果页中。
搜索引擎的主要有三个功能板块:
1、抓取:在网络上抓取内容,查看网站找到的每个URL的代码对于的相应内容。
2、索引:存储和组织在爬网过程中找到的内容,页面进入索引后,就会在运行中显示为相关查询的结果。
3、排名:提供最能回答用户查询的内容,这意味着搜索结果的排序方式从最相关到最不相关。
抓取是一种发现过程,搜索引擎在其中发现一组机器人也就是我们所说的搜索引擎蜘蛛,来寻找新的和更新的内容。内容可以有所不同,可以是网页,图片,视频,PDF等但无论格式如何,内容都是通过链接发现的。
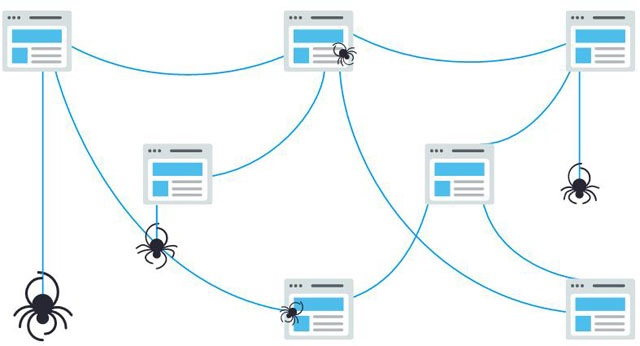
Googlebot首先获取一些网页,然后按照这些网页上的链接查找新的URL。通过沿着链接的这种路径跳动,蜘蛛可以找到新内容并将其添加到名为Caffeine的索引中,以后当用户搜索到该URL上的内容为很适合。搜索引擎处理并存储他们在索引中找到的信息,索引是他们发现并认为足以为用户服务的所有内容的庞大数据库。当有人进行搜索时,搜索引擎会在索引中搜索高度相关的内容,然后对这些内容进行排序,以解决用户的查询,我们搜索结果的相关性排序称为排名。通常,我们可以假设网站的排名越高,搜索引擎认为该网站与查询的相关性就越高。
有可能阻止我们的部分或全部网站访问搜索引擎爬网程序,或者指示搜索引擎避免将某些页面存储在其索引中。尽管我们这样做有一定的原因,但是如果我们希望用户找到我们的内容,则必须首先确保抓取工具可以访问该内容并将其编入索引。否则,一切的优化工作将都是徒劳。我们都认为SEO排名是由数据来决定的,所以是客观的,公平的。其实不然!许多初学者想知道特定搜索引擎的相对重要性。大多数人都知道Google拥有最大的市场份额,但是对Bing,Yahoo和其他公司进行优化对它有多重要呢? 事实是,尽管存在30多个主要的网络搜索引擎,但SEO社区实际上只关注Google。因为绝大多数人都在Google搜索网站。如果我们将Google Images,Google Maps和YouTube包括在内,则超过90%的网络搜索是在Google上进行的,这是Bing和Yahoo的总和的近20倍。
介绍了搜索引擎的主要功能原理,下面我们来分析搜索原理的第一部分—爬行抓取。
正如我们刚刚了解到的那样,确保对我们的网站进行爬网和建立索引是在搜索引擎结果页中显示的先决条件。如果我们已经有一个网站,则最好先查看索引中有多少页面,然后再开始。这将对Google是否正在爬网并找到我们想要的所有页面,以及我们不需要的所有页面产生一些深刻的见解。检查索引页面的一种方法是高级搜索运算符“ site:aaa.com”。转到Google,然后在搜索栏中输入“ site:aaa.com”这将返回Google在其指定网站的索引中具有的结果。Google所显示的结果数量并不确切,但是它确实使我们对网站上哪些页面建立了索引以及它们当前在搜索结果中的显示方式有一个明确的了解。为了获得更准确的结果,请在Google Search Console中监控和使用“索引覆盖率”报告。如果我们目前没有免费的Google Search Console帐户,可以注册一个。使用此工具,我们可以提交网站的网站地图,并监视实际上已将多少已提交的页面添加到Google的索引中。
如果我们没有在搜索结果中显示任何位置,则可能有以下几种原因:
1、我们的网站是全新的,尚未进行爬网。
2、我们的网站未从任何外部网站链接到。
3、我们网站的导航使机器人很难有效地对其进行爬网。
4、我们的网站包含一些称为蜘蛛指令的基本代码,这些基本代码会阻止搜索引擎。
如果我们使用Google Search Console或“ site:aaa.com”高级搜索运算符,但发现索引中缺少某些重要页面和/或某些不重要的页面被错误地编入索引,则可以进行一些优化 实施,以更好地指导Googlebot我们要如何抓取网络内容。告诉搜索引擎如何抓取我们的网站可以使我们更好地控制索引中的内容。大多数人都考虑过确保Google可以找到自己的重要页面,但是很容易忘记,有些页面可能是我们不希望Googlebot找到的。这些内容可能包括诸如内容稀少的旧URL,重复的URL特殊的促销代码页,登台或测试页之类的内容。
要使Googlebot远离我们网站的某些页面和部分,请使用robots.txt。Robots.txt文件位于网站的根目录中,建议我们应该和不应该搜索网站的哪些部分,以及它们搜索网站的速度,通过特定的robots.txt指令。那么,Googlebot如何处理robots.txt文件呢?
1、如果Googlebot找不到网站的robots.txt文件,则会继续抓取该网站。
2、如果Googlebot找到了网站的robots.txt文件,则通常会遵守建议并继续抓取该网站。
3、如果Googlebot在尝试访问网站的robots.txt文件时遇到错误,并且无法确定该网站是否存在,它将不会抓取该网站。
抓取是Googlebot离开前将在我们的网站上抓取的URL的平均数量,因此抓取预算优化可确保Googlebot不会浪费时间在不重要的页面上进行抓取,而忽略了重要页面的风险。在拥有成千上万个网址的大型网站上,抓取预算是最重要的,但是阻止抓取工具访问我们绝对不在意的内容绝不是一个坏主意。只要确保不阻止爬网程序访问我们添加了其他指令的页面即可。如果某个页面禁止了Googlebot,将无法看到该页面上的说明。当然,并非所有的网络机器人都遵循robots.txt。有恶意的人会构建不遵循此协议的漫游器。实际上,一些不良用户会使用robots.txt文件来查找我们的私人内容所在的位置。尽管将爬网程序阻止在诸如登录和管理页面之类的私人页面中以使其不显示在索引中似乎合乎逻辑,但将这些URL的位置放在可公开访问的robots.txt文件中也意味着存在恶意意图的人可以更轻松地找到它们。最好让这些页面NoIndex并在登录表单后设置它们,而不是将它们放在robots.txt文件中。
通过将某些参数附加到URL,某些站点在多个不同的URL上提供相同的内容。如果我们曾经在线购物,则可能已通过过滤器缩小了搜索范围,每次优化时,URL都会略有变化。Google如何知道要提供给用户的URL版本? Google在自行找出代表性URL方面做得很好,但是我们可以使用Google Search Console中的URL Parameters功能来确切告诉Google我们希望他们如何对待网页。如果我们使用此功能告诉Googlebot“不使用参数抓取网址”,那么我们实际上是在要求从Googlebot隐藏该内容,这可能会导致这些页面从搜索结果中删除。如果这些参数创建了重复的页面,那就是我们想要的,但是如果我们希望这些页面被索引,那是不理想的。
蜘蛛可以找到我们所有的重要内容吗?既然我们已经知道了确保搜索引擎抓取工具远离我们不重要的内容的一些策略,那么让我们了解一下可以帮助Googlebot查找重要页面的优化方法。有时,搜索引擎将能够通过爬网找到我们网站的某些部分,但是其他页面或部分可能由于某种原因而被遮盖。重要的是要确保搜索引擎能够发现我们想要索引的所有内容而不仅仅是首页。如果我们要求用户在访问某些内容之前登录,填写表格或回答调查,搜索引擎将不会看到那些受保护的页面。爬网程序是不会登录的。机器人程序无法使用搜索表单。有些人认为,如果他们在自己的网站上放置搜索框,则搜索引擎将能够找到其访客搜索的所有内容。非文本媒体形式如图片,视频,GIF等不应用于显示希望被索引的文本。尽管搜索引擎在识别图片方面变得越来越好,但并不能保证它们现在仍能够阅读和理解图片。始终最好在网页的<HTML>标记内添加文本。就像爬虫需要通过其他站点的链接来发现我们的站点一样,它也需要我们自己站点上的链接路径来引导页面之间的链接。如果我们有要搜索引擎查找的页面,但未从任何其他页面链接到该页面,则与隐藏页面一样好。许多网站都犯了严重的错误,即以搜索引擎无法访问的方式来构建导航结构,从而阻碍了其在搜索结果中列出的功能。
常见的导航错误可能使爬网程序无法看到我们的所有站点:移动导航显示的结果与pc导航不同,菜单项不在HTML中的任何类型的导航,例如启用JavaScript的导航。Google在抓取和理解Java方面已经做得更好,但是仍然不是一个完美的过程。确保某些东西被Google找到,理解和建立索引的更可靠方法是将其放入HTML中。个性化或相对于其他类型的访问者显示独特的导航方式似乎掩盖了搜索引擎爬虫,忘记通过导航链接到我们网站上的主页-记住,链接是爬虫遵循的进入新页面的路径。这就是为什么网站必须具有清晰的导航和有用的URL文件夹结构至关重要的原因。
信息体系结构是一种组织和标记网站上的内容以提高用户效率和可发现性的实践。最好的信息体系结构是直观的,这意味着用户不必费心思量即可浏览我们的网站或查找内容。那么可以使用网地图,网站地图就是它的外观,爬网程序可用来发现我们的内容并将其编入索引的站点上URL列表。确保Google查找优先级最高的页面的最简单方法之一是创建符合Google标准的文件,然后通过Google Search Console提交文件。尽管提交网站地图并不能代替良好的站点导航,但可以肯定地帮助爬网程序遵循通往所有重要页面的路径。确保仅包含要由搜索引擎索引的URL,并确保为抓取工具提供一致的方向。例如,如果我们已经通过robots.txt阻止了该网址,则不要在我们的网站地图中包含该网址,或者在我们的网站地图中包含重复的网址,而不是首选的范本。如果我们的网站没有其他链接到该网站,则仍可以通过在Google Search Console中提交XML网站地图来对其进行索引。不能保证他们将在索引中包含一个提交的URL,但是去尝试一下。
有很多朋友有过这样的疑问:蜘蛛尝试访问我们的URL时是否出错?
其实,在搜索我们网站上的URL的过程中,蜘蛛可能会遇到错误。我们可以转到Google Search Console的“抓取错误”报告,以检测可能发生此错误的网址该报告将向我们显示服务器错误和未发现的错误。服务器日志文件还可以向我们显示此信息,以及其他信息如抓取频率的数据库,但是由于访问和剖析服务器日志文件是一种更高级的策略。我们必须先了解服务器错误和“未找到”错误,然后才能对抓取错误报告进行有意义的任何操作。
4xx代码:当搜索引擎抓取工具由于客户端错误而无法访问我们的内容时
4xx错误是客户端错误,这意味着请求的URL语法错误或无法实现。最常见的4xx错误之一是“ 404 –未找到”错误。这些可能是由于URL错字,已删除页面或断开的重定向而引起的,仅举几个例子。当搜索引擎搜索到404时,它们将无法访问该URL。当用户点击404时,他们可能会感到沮丧而离开。
5xx代码:当搜索引擎抓取工具由于服务器错误而无法访问我们的内容时
5xx错误是服务器错误,这意味着网页所在的服务器无法满足用户或搜索引擎访问该页面的请求。在Google Search Console的“抓取错误”报告中,有一个专门针对这些错误的标签。这些通常是由于对URL的请求超时而导致的,因此Googlebot放弃了该请求。查看Google的文档,以了解有关解决服务器连接问题的更多信息。
不过,有一种方法可以告知用户和搜索引擎我们的页面已301(永久)重定向。

假设我们将页面从aaa.com/b-c/移至aaa.com/d/。搜索引擎和用户需要一个桥梁,以从旧URL过渡到新URL。该桥是301重定向。当我们实施301时:当我们未实施301时:链接资产将链接的资产从页面的旧位置转移到新URL。如果没有301,则来自先前URL的权限不会传递到URL的新版本。索引帮助Google查找和索引页面的新版本,仅在我们的网站上出现404错误并不会损害搜索性能,但是让排名/被投放的页面404可能会导致它们不在索引之列,排名和访问量随之而来。用户体验确保用户找到他们要查找的页面。允许访问者单击无效链接会将他们带到错误页面,而不是预期的页面,这可能会用户降低体验。
301状态代码本身表示该页面已永久移动到新位置,因此请避免将URL重定向到不相关的页面,即原来的URL内容实际上不存在的URL。如果页面正在为查询排名,而我们将其301链接到具有不同内容的URL,则该页面的排名可能会下降,因为与该特定查询相关的内容不再存在。301负责任地移动URL。我们还可以选择302重定向页面,但这应该保留给临时移动,以及在不太需要传递链接净值的情况下。302有点像绕道而行我们暂时通过某条路径吸引流量,但不会永远这样。所以,一定要注意重定向链接。如果Googlebot必须进行多次重定向,可能很难到达我们的页面。Google称这些为“重定向链”,他们建议尽可能限制它们。如果我们将aaa.com/1重定向到aaa.com/2,然后再决定将其重定向到aaa.com/3,则最好消除中间人,只需将aaa.com/1重定向到aaa.com/3。在确定我们的网站针对爬网能力进行了优化之后,下一个优化操作就是要确保它可以被索引。
(转载请注明转自:www.wangzhan.net.cn,谢谢!珍惜别人的劳动成果,就是在尊重自己!)
上一篇:搜索引擎的工作原理之索引
下一篇:SEO是什么,为什么那么重要?
24小时服务热线:4000-135-120转6
业务 QQ: 444961110
渠道合作: 444961110@qq.com
河北供求互联信息技术有限公司(河北供求网)诞生于2003年4月,是康灵集团旗下子公司,也是河北省首批从事网站建设、电子商务开发,并获得国家工业和信息化部资质认证的企业。公司自成立以来,以传播互联网文化为已任, 以高科技为起点,以网络营销研究与应用为核心,致力于为各企事业单位提供网络域名注册、虚拟主机租用、网站制作与维护、网站推广和宣传、网站改版与翻译、移动互联网营销平台开发与运营、企业邮局、网络支付、系统集成、软件开发、电子商务解决方案等优质的信息技术服务,与中国科学院计算机网络信息中心、腾讯、百度、阿里巴巴、搜狗、360、电信、联通、中国数据、万网、中资源、阳光互联、点点客、北龙中网、电信通等达成战略合作伙伴关系。